METHODOLOGY
theory and process of Object Americana


6e12{skullgun2}
Greetings! If you have found this page, you must be very interested in the specific methodology that has gone into producing some of the world's first AI-driven sculpture. As an artist and Machine Intelligence practitioner, I believe I have an ethical duty to make Object Americana as transparent as possible.
Below, you will find a detailed explanation of the theory and motivations behind the work, as well as a technical overview of the process itself. The technical walkthrough will be based upon the first fully-realized prototype of the project, a combination between a human skull and an AR-15 assault rifle.
+
=
Object Americana began as an exploration of Machine-agent creativity. This concept led me to think about how I view my own creativity; I view it as primarily synthetic. To the combinatory act is one of the fundamental building blocks of creativity and happens to the block I am most adept at.
The second motivation for combining things is the concept of semiotics, several fields of research generally considered a sibling of linguistics. The base concept is that meaning is generated as a relationship between a signifier and the thing it signifies. Through the study of semiotics, one (such as a mid-20th century philosopher) may break down societal phenomena into important constituent concepts which might not be apparent at first glance. This project attempts to reverse-engineer this process. Instead of looking at signifiers and determining what they signify, Object Americana starts from the middle and works outward toward new signifiers and the signified concepts they might entail. I hope this notion is captured by the "object combination equations" I have placed throughout this website, as seen above. ↑
The true depth of the combinatory act is revealed: if one begins combining objects with well-understood symbolic value, one is necessarily creating new symbols with open-ended interpretations. Signposts that arise at the intersection of two streets but which point off perpendicular to both of them. The goal of Object Americana is to develop new ways of understanding the concept of the United States.
skull--ar15 training sequence
0e35
0e51
1e57
1e103
2e70
3e98
5e89
5e119
5e120
6e12
26e2
32e124
We are lucky enough to live in interesting times. Machine Intelligence is a major agent (so to speak) turning the wheel of history. I refer to 'Machine Intelligence' to emphasize its parallel rather than subservient position to our own. Speaking especially of the wheel of history, I believe we as a species would do quite well to try and end our habit of thinking of silicon-based intelligence as something that exists solely to serve our needs, inevitably economic.
Indeed, what intrigues me most about the Machine agents has already been apparent for many years: Machines have a totally different perceptive ability than humans. They use sensor data and mathematics to form impressions and opinions about the world around them. This ability is already exploited in countless ways in our daily lives by way of the many industries already touched by the new science of 'Machine Learning'.
Machine Learning is a process of encoding a vast amount of data into Machine-comprehensible datapoints in a virtual region called the latent space. Once these data are thus encoded, the Machine can draw inferences about fresh data shown to it about where that fresh data likely resides in its established knowledge-field. This process is the basis for nearly all Machine Learning applications, from text translation to self-driving cars. If you take this concept and turn it back in on itself, you get the radical notion of Generative Machine Intelligence.
The field of Generative Machine Intelligence describes to me an entirely new avenue of perception available to Machines and through them, us Humans. Generative Machine Intelligence takes this avenue of perception and runs with it to its logical conclusion: creation. The Machine is instructed to use its latent space to create novel datapoints that did not previously exist in the dataset. What is perhaps the most exciting thing about this incredible process is that a Machine may be trained to interpret many different things in its latent space and then generate examples of data interpolated between existing things. This ability to seamlessly interpolate between understood things does not come naturally to Human agents at all. It is a truly novel perceptive ability, and it is the driving force behind Object Americana.
The bizarre and intriguing appearance of this Generative Machine producing its own versions of combined objects is depicted in the 'training sequences' displayed for each combined-object sculpture throughout this website, as above. ↑ (not appearing on mobile platforms)
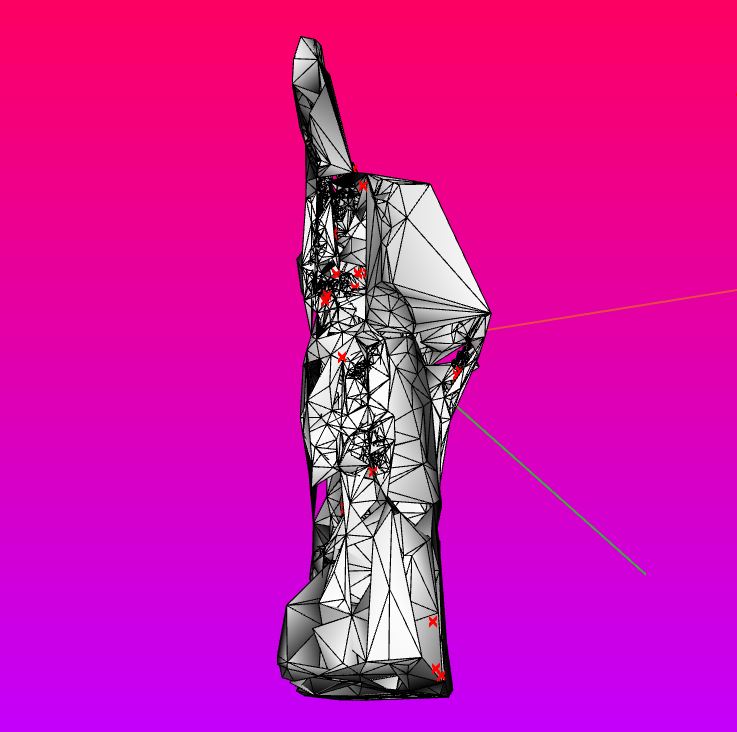
Well, I am a sculptor! I am a sculptor because 3D space has always been my primary means of expression. My background is in architecture, sculpture, and 3D printing. 3D printing is especially important because it allows objects which formerly could only be digital to come to life in the physical world. Object Americana embraces the physicality of sculpture while turning it on its head. This project is an attempt to create a new genre of sculpture that is fundamentally digital. Using a generative Machine Intelligence to synthesize new America-signifying objects is an act of creation that can only occur in the digital realm; by using a 3D-printing machine to bring those objects into the real work, I complete the strange circle and establish a new quadrant in the realm of sculpture: fully digital, fully physical, and fully rooted in Machine Intelligence.

I am an American artist; even if I left the country and began life anew elsewhere, this would never change, especially since America sees itself as a global hegemony. Further, I am from a state called Michigan which embodies many of the most egregious qualities of my fair country and which bears the distinction of being the prototyping grounds for many of them. It is also a place of great natural beauty and inspiration, and it too has felt the wheels of history on its rough roads. Historically, it manufactured plenty of them. Being from that place created in me a deep sense of loss and tragedy. It is a region defined by how great it was a generation and a half before I was born, and the sense of this was everywhere, even growing up in the affluent college town I hail from.
The United States of America is an empire in decline. I do not mourn the slow senescence of a empire. Rather, I am trying to observe it, comment on it, perhaps make sense of it, perhaps make confusion of it. This final piece of the artistic puzzle is mine and mine alone.
With the conceptual foundation laid, it came time to build the structure of the project itself. Immediately, the question of which objects precisely to hybridize becomes very important. Early on in the project, I came up with a list myself: a darkly humorous mix of weapons of war, TSA security devices, trucks, and of course, the All-Seeing Eye. However, I soon realized that this was not adequate to the task at hand. My own list of objects reflected too much of my own taste and obscure amusement at the topic. Contrary to that notion, a central aspect of Object Americana and moreover the Machine-Intelligence-based object-combining alchemy at the heart of it is the palpable feeling I have of partnering with a force beyond my control or understanding.
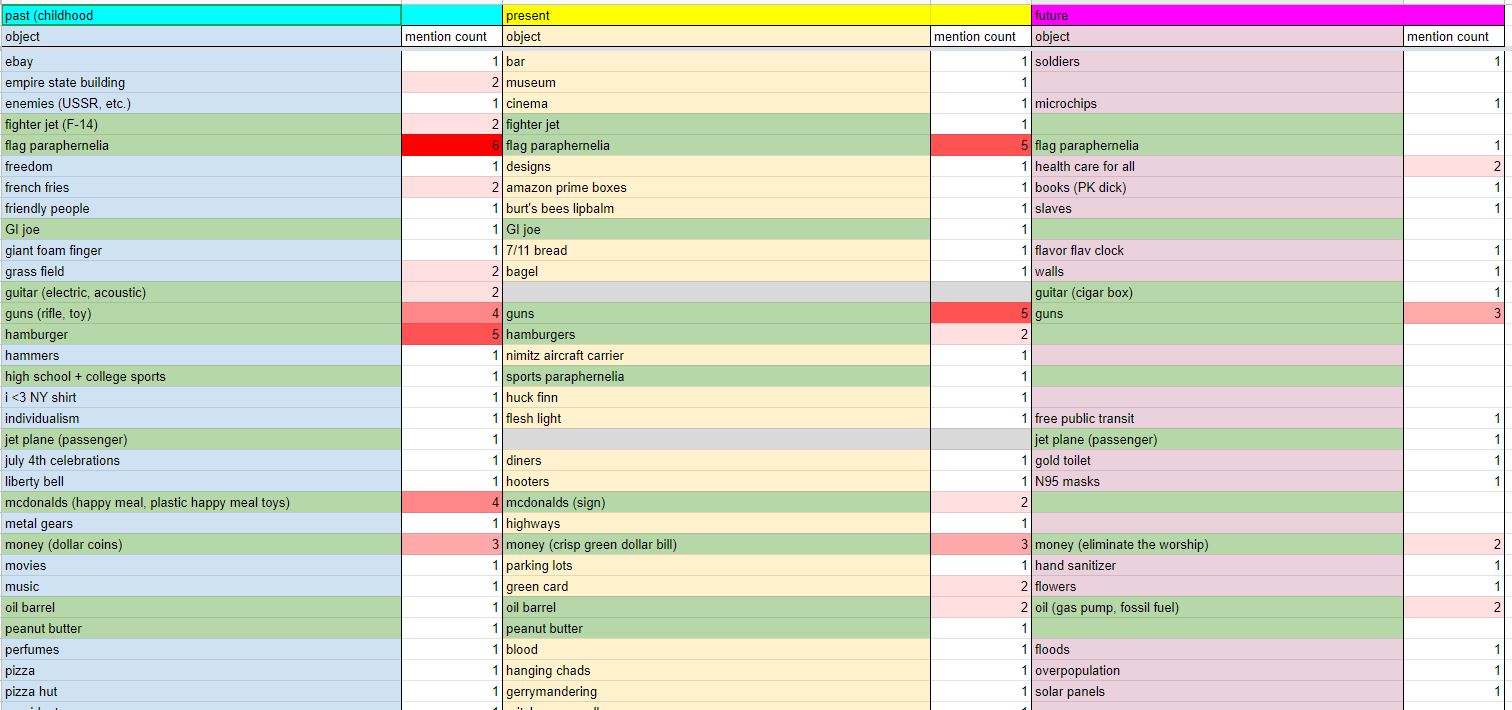
The solution to the problem was to create a questionnaire for people to respond to and take their responses as a much more genuine reflection of the concept of "Americana" than anything I could personally come up with. Thus, the first step of Object Americana is a bit of crowd-sourced wisdom. The poll was primarily focused on immigrants, people who were born in other countries and raised there for a significant portion of their life, and received 31 full respondent answer sets. Not a huge number but plenty for our purposes. The questions were divided into sections about the past, present, and future, and asked about the objects people associate with the USA from those three eras in their own personal history.
A section of the response spreadsheet is visible above ↑. The results of the questionnaire will shortly become apparent!
We have established the conceptual underpinnings and motivations behind the project. It is time to begin the alchemy itself. This section will take the form of a list of the technical steps in the choreographed process that is the actual work of Object Americana. This process modifies and extends the work of Dong Wook Shu, Sung Woo Park, and Junseok Kwon in their paper 3D Point Cloud Generative Adversarial Network Based on Tree Structured Graph Convolutions1 which is a 3D point-cloud GAN as the title implies. A GAN, Generative Adversarial Network, is a type of Machine agent that learns through trying to fool itself into believing the things it is generating are real examples of data2, similar to the process described in "Why Machine Intelligence?" above. A point-cloud is a set of point data in 3D space; this is a commonly produced data type of 3D scanners, but they can also be created algorithmically as I have done here. Generally, a single point-cloud represents the surface of a single object; the points in the cloud reside directly on the surface of the object.
The full steps of Object Americana are as follows, arranged as a description of the step followed by (the tool which is used to carry it out). Click the numbers for easier navigation:
1 → pick objects (questionnaire data + Human intuition)
2 → Generate point clouds (Grasshopper for McNeel Rhinoceros, a CAD program)
3 → Make the point clouds into Machine-readable datasets (Python file processing using custom-written scripts)
4 → Train new GAN Machine agent (TreeGAN, a Machine Intelligence that runs on PyTorch for Python)
5 → Extract Machine-generated point clouds (Python)
6 → Import and do preliminary algorithmic meshing of GAN point clouds (Grasshopper)
7 → Compile training session meshes into video showing training process (Grasshopper)
8 → Examine video, pick 'contenders' for final object (Grasshopper)
9 → Manually knit mesh fragments of final contender into solid object (≅12 hours of artistic labor in Rhino)
After conducting the questionnaire, I found the objects that people mentioned the most in each category. Of this list of candidates, I selected two from each category for the combination. This selection was based both on the number of mentions as well as my own Human intuition as to which objects would make good combinations and represent the chronological category effectively.
←

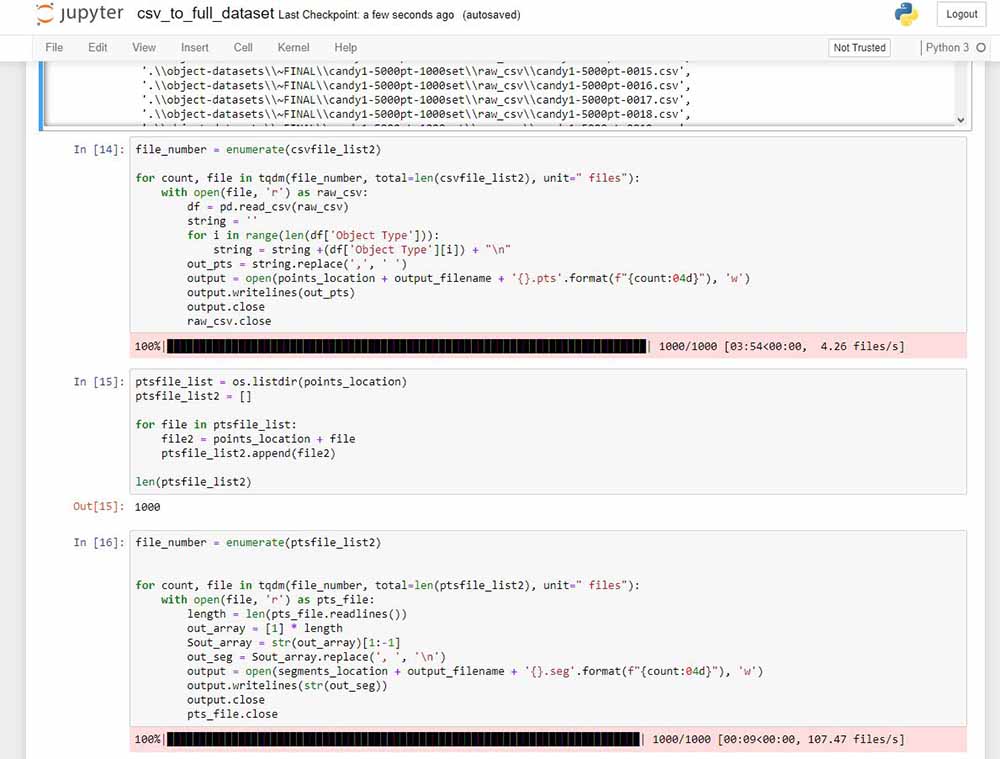
This video demonstrates the algorithmic point-cloud generation process. Grasshopper, a parametric design program, runs though 1000 random seeds for the points on the surface of the skull mesh and saves them to separate .csv (comma-separated value, a common data-exchange format) files.
→
The 1000 point-cloud csvs from the previous step are processed using Python to clean them up and produce a full dataset usable by TreeGAN, the Machine Intelligence which will be looking at them and combining them. The cleaning process is shown in the first half of this image. TreeGAN is able to interpret segmentation data, but this is beyond the scope of this project. As such, we must also generate 1000 files which simply contain a "0" (indicating they all belong to the same segment) for each point in the point-cloud they correspond to. This is the second half of the image. If you look closely, you can see that generating files full of zeros is much faster than cleaning actual data, 107.47 files/second compared to 4.26!
←
Once the datasets are produced, we can begin training a new TreeGAN agent on our chosen objects. These images show snapshots of a 3D point-cloud training process. The training dataset is a chair, the very first out-of-the-box test I tried. You can clearly see how the Machine becomes better at understanding and reproducing the data over time. An epoch means that the Machine has gone over the entire dataset one time, a term common to many branches of Machine Learning.
→
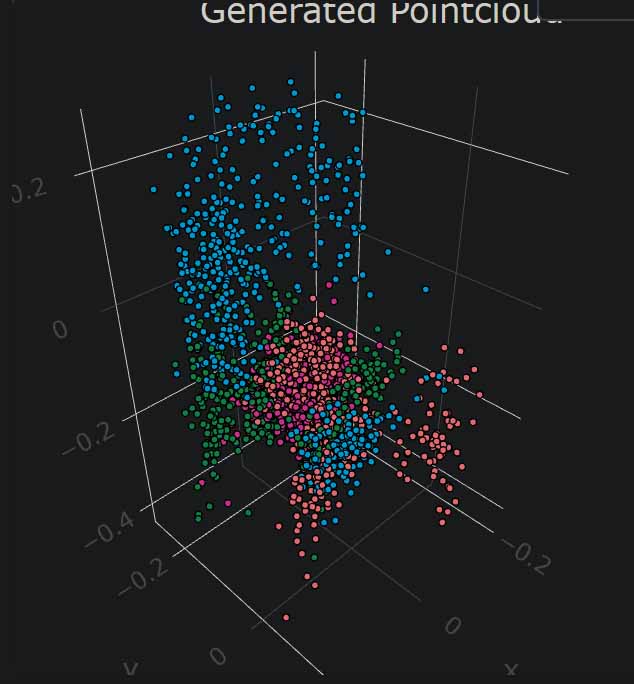
6 epoch chair
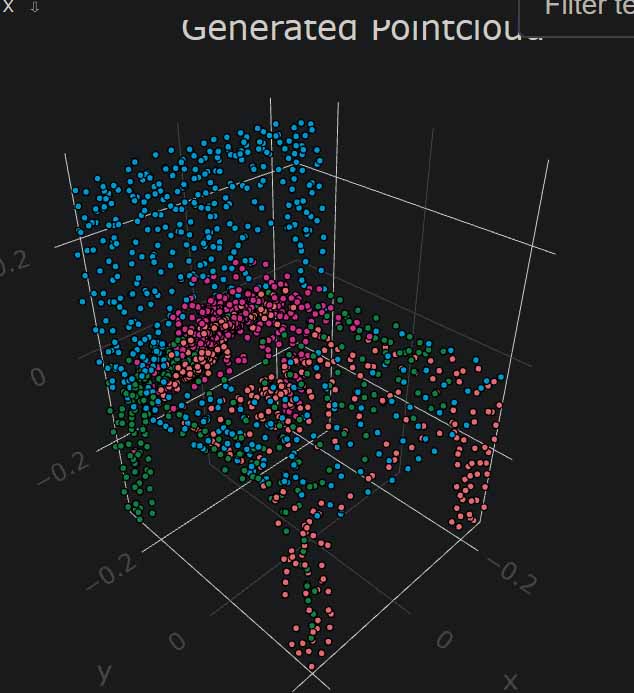
62 epoch chair
Much like in step 3, a small amount of pythonic file-scrubbing is required to take our Machine-generated point-clouds out of the Machine's memory and put them back into the 3D modeling program. This required putting a shunt into TreeGAN, letting it output its point-clouds as it learned. Once we have those raw point-cloud tensors, representing each step of the training process as it progresses, we must further convert them back into readable 3D data. This is accomplished using RegEx (Regular Expressions) for Python, a method of manipulating strings of text.
←
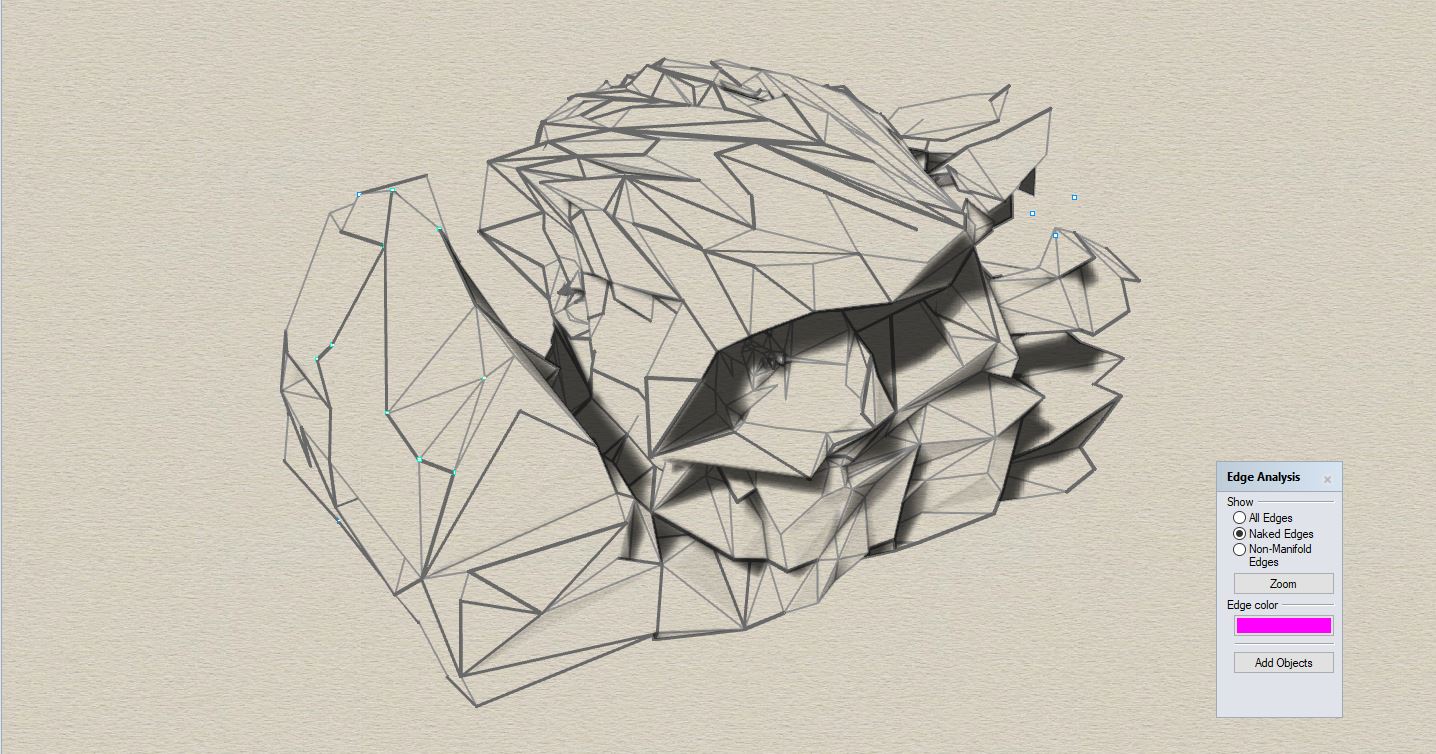
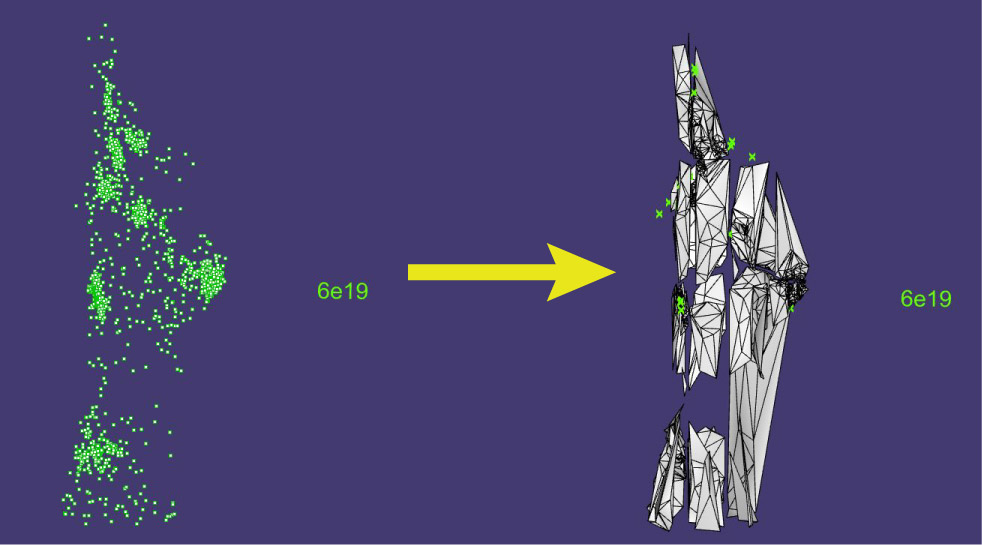
The sixth step is to do a preliminary algorithmic meshing of our freshly-generated point clouds. A mesh is a digital 3D object composed of vertices and faces. Each face is a triangle defined by three vertices at its corners; a mesh is usually made of many such faces connected at their edges. To conduct further analysis on our point-clouds, we use an algorithm called Delauney triangulation on top of a grouping method called an Octree in order to produce a preliminary set of meshes from our point-cloud.
→
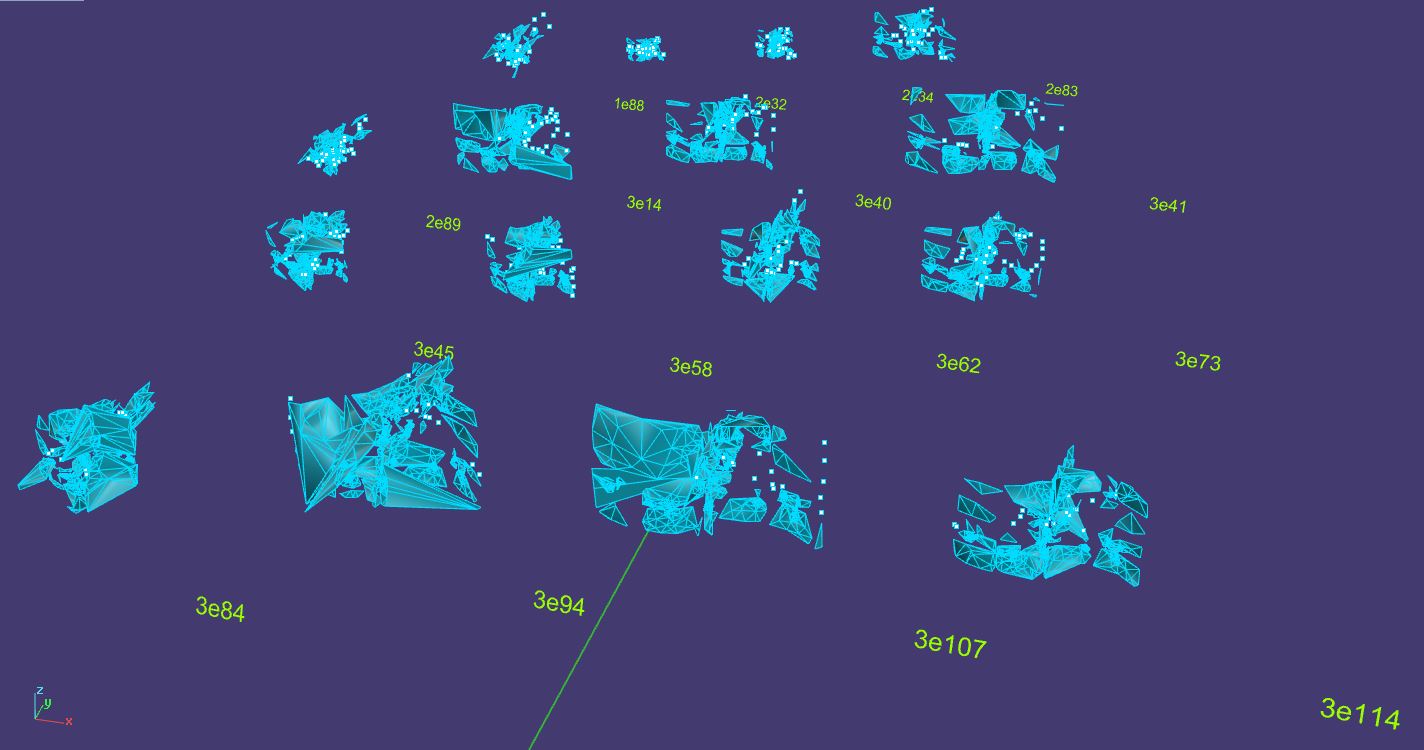
Now that our point-clouds have some skin on their bones, the next step is to compile the full training set into a video. This serves two purposes: the first is as a form a direct documentation of the project; the second is so that we can watch the video closely and determine if this particular object combination results in viable combined object meshes. These resulting videos are quite striking to behold; they represent a much more detailed view of the training process shown in step 4. This sort of visualization of a 3D GAN has to my knowledge never been achieved before this project.
←
The second-to-last step is perhaps one of the most difficult of all. We must determine which of the thousands of Machine-driven meshes from each object combination must be made into the final sculpture, once again drawing upon our Human intuition. This process involves slowly looking through the full list of generated meshes one-by-one, manually writing down promising "contenders." The very best 20 or 30 are extracted and put back into the 3D file, to see them side-by-side and judge them on their merits. Eventually, the list pared down further and further until one contender stands alone as the point-cloud that give rise to the final object mesh.
While this step is crucial, it is also heavily reliant on the Human's judgement and intuition. As this project represents a true collaboration, I make no effort to obfuscate the point that this sort of decision-making is limited to my own vision as an artist. Sadly, my Machine partner cannot currently take part.
→

liberty--mcds contenders
wavingflag--ar15 contenders
Finally! The last step of the process is a tedious but immensely enjoyable one. I, the Human, must decide what's 'in' and what's 'out,' quite literally! Once the final contender is selected, it must be converted from a set of fragment meshes into a single, solid, complete one. The process of manually stitching the algorithmic meshes together requires an idea of where precisely the surface of the finished object will be.
I then proceed to manually draw individual mesh faces, point by point, triangle by triangle, and join them onto the finalized mesh. This can take from four to twelve hours or more!
←
That concludes the choreography of Object Americana! It's been a long journey, thank you for taking the time to voyage with us! I hope you have enjoyed learning about this new sculptural process. You can use the buttons at left to check out the final sculptures of the project, as well as go back to the homepage. Cheers, and stay tuned!
―
1 Shu, Dongwook, Park, Sung Woo, and Kwon, Junseok. "3D Point Cloud Generative Adversarial Network Based on Tree Structured Graph Convolutions." 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019. https://doi.org/10.1109/iccv.2019.00396.
2 "Introduction | Generative Adversarial Networks | Google Developers." Google. https://developers.google.com/machine-learning/gan.